class: center, middle name: title # CS 10C - Priority queues ![:newline] .Huge[*Prof. Ty Feng*] ![:newline] .Large[UC Riverside - SQ 2026] ![:newline 6]  .footnote[Copyright © 2026 Joël Porquet-Lupine and Ty Feng - [CC BY-NC-SA 4.0 International License](https://creativecommons.org/licenses/by-nc-sa/4.0/)] ??? - Quick topic for today - You recognize queue in the name, so you already now half of it - Before diving in the definition of what a priority queue is, let's see a couple of examples that justify the need for this new type of queue --- layout: true # Introduction --- ## Process scheduling Objectives: - Execute multiple processes until completion - Keep the system responsive -- ![:newline 1] ### Example scenario 1. Start long compilation 1. Refresh canvas page 1. Send IM message 1. Receive email notification ![:newline 1]  -- ![:newline 1] - Are processes executed until completion? - Will the system feel responsive? --- ### Round-robin scheduling - Add processes to a *(typically FIFO)* queue - Execute them for equal chunks of time  - Will the system feel more responsive? Can we do better? ??? - For RR scheduling, we could do with a regular queue as we already know it -- ![:newline 1] ### Priority scheduling - Associate priority with each process - E.g., short processes get higher priority - Execute the processes with the highest priority first  ??? - For priority scheduling, we couldn't do it with regular queue, need another ADT --- layout: true # Priority queue ADT --- ## Definition Queue where each item is associated to a priority (i.e., a comparable key): - **Push**: add item and associated priority - **Pop**: remove item with *highest* priority  ![:newline 1] - Operations are also sometimes known as: - Push => *Insert()* - Pop => *GetMin()* or *Pull()* ??? - Push/Pop is the semantic for the std library - Usually in the literature, insert and getmin --- ## Typical API .small[ ```C // Return number of items in priority queue size_t Size(); // Return top of priority queue T& Top(); // Remove top of priority queue void Pop(); // Insert item and sort priority queue void Push(const T &item); ```  ] -- ## Naive implementations .lcol66[ - Sorted list - Keep sorted by priority when pushing - Pop highest priority item from front ] .rcol33[  ] ??? - Don't talk about complexity yet, just principle -- ![:flush 0] .lcol66[ - Binary Search Tree (self-balanced) - Restructure tree by priority when inserting - Return highest priority item from minimum of tree ] .rcol33[  ] --- ### List implementation .lcol.footnotesize[ ```C template <typename T> class PriorityQueue { ... private: std::list<T> items; }; template <typename T> size_t PriorityQueue<T>::Size() { return items.size(); } ```  ] .rcol.footnotesize[ ```C template <typename T> T& PriorityQueue<T>::Top(void) { if (!Size()) throw std::underflow_error( "Empty priority queue!"); return items.front(); } template <typename T> void PriorityQueue<T>::Pop() { if (!Size()) throw std::underflow_error( "Empty priority queue!"); items.pop_front(); } template <typename T> void PriorityQueue<T>::Push(const T &item) { // Find first bigger element than @item auto pos = std::lower_bound( items.begin(), items.end(), item); // Insert before it items.insert(pos, item); } ```  ] .lcol[ ![:newline 3] - Entirely based on `std::list` - Insertion in order - With a bit of error management ![:newline 1] - What is the complexity of each method? ] ??? - By default, `std::list` doesn't have error management (eg front() on an empty list is undefined behavior) - Same as when we were using vector or forward list with stack/queue ![:newline 1] - Note that we could also use an unsorted list and pay the opposite complexity (insertion in O(1) and pop in O(n)) - Although complexity would be perfectly inverted, is it really equivalent? - No because pop in O(n) is really in n (have to traverse the entire to find the minimum); where push in O(n) is likely not to be in n often. --- ### Binary Search Tree implementation A priority queue can also be entirely mapped onto a Binary Search Tree implementation: .lcol60[ - `Top()` - Use `Min()` function - `Pop()` - Use `Remove(Min())` function - `Push()` - Same as BST What is the complexity for each method? ] .rcol40[  ] -- ![:flush 1] ### Conclusion on naive implementations - A list implementation gives `Top()/Pop()` in $O(1)$ - But `Push()` in $O(n)$ - A BST implementation gives `Push()` in $O(\log n)$ - But `Top()/Pop()` in $O(\log n)$ - How to get the best of both worlds?... --- layout: true # Binary Heap --- ## Definition - Most common data structure for implementing priority queue ADT - When used without a qualifier, a *heap* usually refers to this particular implementation - A heap is a binary tree with two properties - Heap-order property - Structure property - Some operations can break these properties (e.g., insertion, removal) - Simple restructuring mechanisms  ??? - Invented by Williams in 1964 ![:newline 1] - How is the tree in the example? Complete! - every level is completely filled, expect the last one, and nodes are packed to the left --- template: title --- layout: false # Recap ## Priority queue .lcol[ - Abstract data type - Pop item with highest priority first ] .rcol[  ] ![:flush 1] ## Binary Heap .lcol[ - Data structure to implement a priority queue - Heap-order property - Structure property ] .rcol[  ] .comment[ .lcol[ ### Push - Insert at end - Percolate up  ] .rcol[ ### Pop - Copy last node over root node - Percolate down  ] ] --- layout: true # Binary Heap --- ## Heap-order property Two types of heap: - **min-heaps**: each node's key is less than or equal to each of its children - **max-heaps**: each node's key is greater than or equal to each of its children .lcol[  .center.footnotesize[Example of min-heap] ] ??? - Highlight difference between this organization and binary search trees! - In a heap, we cannot search very efficiently -- .rcol[  .center.footnotesize[Example of broken heap-order] ] -- ![:flush 1] ### Root node property - By design, item with highest priority is always the root - `Top()` is $O(1)$! --- ## Structure property .lcol60[ - A heap is a *complete* binary tree - All levels are completely filled, apart from possibly the last - The last level is packed to the left - Guarantee of height in $O(\log n)$ ] .rcol40[  ] ??? - Two advantages: - Keep height minimal - Make the representation easy! - I showed this representation to you back when I first presented binary trees, several weeks ago now, and told you it would come back later. Now is the time. -- ![:flush 1] ### Easy representation - Completely regular structure which can be represented with a simple array - No need for complicated link management, and fast (level-order) traversal ![:newline 1] .lcol60[  ![:newline 1] - Root is always at index $1$ ] .rcol40[ For node at index $i$ .ref.red[\*]: - Left child at index $2i$ - Right child at index $2i + 1$ - Parent (if not root) at index $\lfloor{\frac{i}{2}}\rfloor$ ] .footnote[ .ref.red[\*] Heap could start at array index 0, but node indexing would become slightly more complex ] ??? ![:newline 1] - One drawback is that the overall size should be guessed beforehand - But we can still resize the array if necessary - Add one to array size to account for wasted first array cell - If array starts at index 0 - Left child at $2i + 1$, right child at $2i +2$, parent at $\lfloor{\frac{i - 1}{2}}\rfloor$ --- ## Implementation: data structure - Min-heap version - Simple array (capacity incremented by 1 for the unused first element) .lcol.footnotesize[ ```C template <typename T> class PriorityQueue { public: // Constructor capacity PriorityQueue(int capacity) : items(capacity + 1) {} ... private: std::vector<T> items; size_t cur_size = 0; ... }; ... size_t PriorityQueue<T>::Size() { return cur_size; } ```  ] ??? - Array allocation -- .rcol.footnotesize[ ```C // Helper methods for indices size_t Root() { return 1; } size_t Parent(size_t n) { return n / 2; } size_t LeftChild(size_t n) { return 2 * n; } size_t RightChild(size_t n) { return 2 * n + 1; } ```  ] ??? - Parent/children index management -- .rcol.footnotesize[ ```C // Helper methods for node testing bool HasParent(size_t n) { return n != Root(); } bool IsNode(size_t n) { return n <= cur_size; } ```  ] ??? - Node testing - HasParent: useful when going up the tree, to know when to stop - IsNode: useful when going down the tree, to know when to stop --- ## Top() .lcol[  ] -- .rcol.footnotesize[ ```C template <typename T> T& PriorityQueue<T>::Top(void) { if (!Size()) throw std::underflow_error( "Empty priority queue!"); return items[Root()]; } ```  ] ??? - At the end of slide, start asking about where to push. Transition to next slide. --- ## Push(): principle .lcol[ - Insert at only possible location that keeps the tree *complete*  ] -- .rcol[ - If heap-order not broken, stop! - Otherwise, swap with parent  ] -- ![:flush 0] .lcol[ - Continue going up tree until heap-order is respected again  ] -- .rcol[ - Strategy known as **percolate up**.red[\*] .footnotesize[ ```bash function PercolateUp(node) { while HasParent(node) && Priority(node) > Priority(parent) do exchange(node, parent) done } ``` ] ![:newline 1] .footnotesize[.ref[\*] Also sometimes known as up-head, bubble-up, heapify-up, swim-up, etc.] ] ??? - Don't know why there are so many names for percolate up - Here, I took the same name as Weiss' textbook - See how HasParent() will be used ![:newline 1] - Live quiz! --- ## Push(): implementation - *Iterative* version of percolate up .small[ ```C template <typename T> void PriorityQueue<T>::PercolateUp(size_t n) { while (HasParent(n) && items[Parent(n)] > items[n]) { std::swap(items[Parent(n)], items[n]); n = Parent(n); } } ```  ] -- - Insertion of new item .small[ ```C template <typename T> void PriorityQueue<T>::Push(const T &item) { if (cur_size + 1 == items.size()) throw std::overflow_error("Priority queue full!"); // Insert at the end items[++cur_size] = std::move(item); // Percolate up PercolateUp(cur_size); } ```  ] ??? - Note that we could resize if we wanted, just keeping it simple here ![:newline 1] - Go back to previous slide to talk about popping and make them guess how to solve it --- ## Pop(): principle .lcol55.small[ - Removing min item leaves hole at root - Last item moved to keep tree *complete* * Move it to root!  ] -- .rcol45.small[ - If heap-order not broken, stop! - Otherwise, swap with smallest child  ] -- ![:flush 1] .lcol.small[ - Continue going down tree until heap-order is respected again  ] -- .rcol.small[ - Strategy known as **percolate down** .small[ ```bash function PercolateDown(node) { while node has a (left) child do pick child with highest priority if Priority(child) > Priority(node) exchange(node, child) else stop done } ``` ] ] --- ## Pop(): implementation .footnotesize[ ```C void PriorityQueue<T>::PercolateDown(size_t n) { // While node has at least one child (if one, necessarily on the left) while (IsNode(LeftChild(n))) { // Consider left child by default size_t child = LeftChild(n); // If right child exists and smaller than left child, then consider right child if (IsNode(RightChild(n)) && items[RightChild(n)] < items[LeftChild(n)]) child = RightChild(n); // Exchange smallest child with node to restore heap-order if necessary if (items[child] < items[n]) std::swap(items[child], items[n]); else break; // Do it again, one level down n = child; } } ```  ] -- .footnotesize[ ```C void PriorityQueue<T>::Pop() { if (!Size()) throw std::underflow_error("Empty priority queue!"); // Move last item back to root and reduce heap's size items[Root()] = std::move(items[cur_size--]); PercolateDown(Root()); } ```  ] --- ## Conclusion ### Running time complexities .center[ | Push | Pop | Top | |-------------|-------------|--------| | $O(\log n)$ | $O(\log n)$ | $O(1)$ | ] ### Other operations - In-place item modification - E.g., when heap/priority queue is used for process scheduling, change priority of a process - `DecreaseItem(T &item, T &delta)` - `IncreaseItem(T &item, T &delta)` ### Other uses - Data structure for *heapsort* sorting algorithm (see later) ![:newline 1] ### Heap variants - 2-3 heap, Binomial heaps, *d*-ary heaps, Fibonacci heaps, Leftist heaps, Skew heaps, Treap, etc. --- ## d-ary Heaps ### Motivation - Binary heaps restrict each node to having exactly 2 children - What if we generalize to allow *d* children per node? - *d* = 3: ternary heap - *d* = 4: quaternary heap - General case: *d*-ary heap -- ![:newline 1] .lcol[ 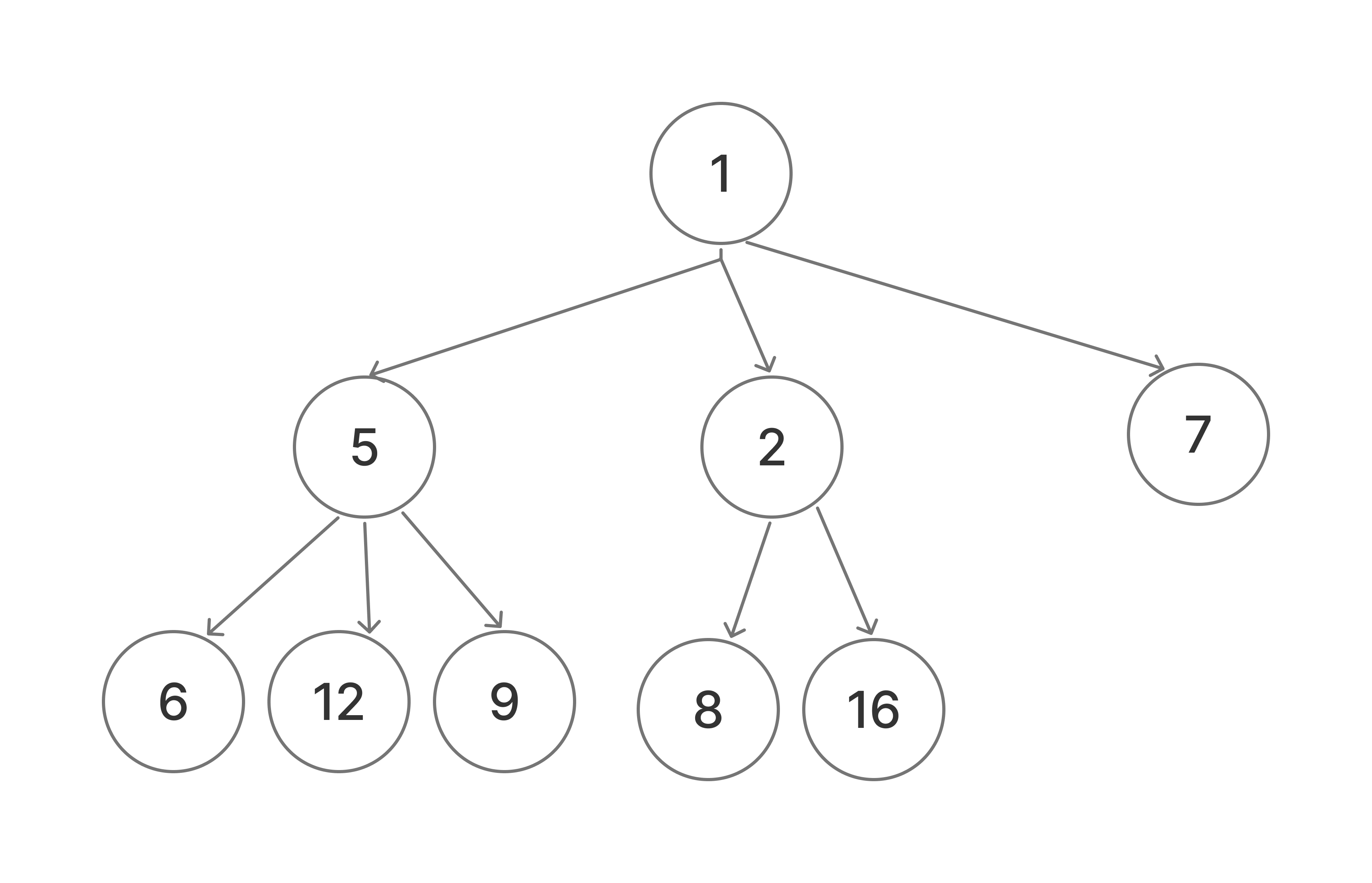 .center.footnotesize[3-ary heap (*d* = 3)] ] .rcol[ ### Key question - Does changing *d* improve performance? - What are the tradeoffs? ] --- layout: false # Priority queue ADT ## Conclusion ### Running time complexities .center[ | Type | Push | Pop | Top | |-------------|-------------|-------------|-------------| | Sorted list | $O(n)$ | $O(1)$ | $O(1)$ | | BST | $O(\log n)$ | $O(\log n)$ | $O(\log n)$ | | Binary heap | $O(\log n)$ | $O(\log n)$ | $O(1)$ | ] --- layout: true # Heapify --- ## Definition - Sometimes, build an entire heap directly out of an initial collection of items ```C // Constructor build heap PriorityQueue(const std::vector<T> &v); ```  ??? - Why? To sort an array: heapsort! -- - Very efficient way to sort an array! - *Heapsort* (see later) -- ![:newline 1] .lcol[ ## Naive approach - Aka Williams' method ```C for (auto k : v) Push(k); ``` ] ??? - Williams was the inventor of binary heaps -- .lcol[ - Total complexity for $n$ items: - $O(n\log n)$, suboptimal - Is there a better way? ] ??? - William's approach: $\sum\_{h=0}^{\lfloor \log n \rfloor} 2^h O(h)$ --- ## Linear approach (Floyd's method) 1. Put all the elements on binary tree, only respecting structure property 2. Percolate down all the elements starting from the first node who has at least one child, and up to the root ![:newline 1] ```C template <typename T> PriorityQueue<T>::PriorityQueue(const std::vector<T> &v) : items(v.size() + 1), cur_size(v.size()) { // Only enforce structure property for (size_t n = 0; n < v.size(); n++) items[n + 1] = v[n]; // Now enforce heap-property for (size_t n = cur_size / 2; n >= 1; n--) PercolateDown(n); } ```  --- ## Demo .lcol[ .footnotesize[ ```C std::vector<int> keys{51, 43, 93, 18, 42, 99, 54, 2, 74}; PriorityQueue<int> pq(keys); ``` ]  ] ??? - 9 nodes total - only 4 nodes have children -- .rcol[ - Heapify from first parent  ] -- .lcol[ - Heapify one level up  ] -- .rcol[ - Up until root  ] ??? - In terms of complexity, the big difference with the naive insertion is that the last level will be in constant time, and the price goes up as we go towards less populated levels - with naive insertion, and for half of the nodes (last level), we will pay full price ![:newline 1] - Floyd's approach: $\sum\_{h=0}^{\lfloor \log n \rfloor} \frac{n}{2^h} O(h)$ - $O(n\sum\_{h=0}^{\lfloor \log n \rfloor} \frac{h}{2^h})$ - $O(n\sum\_{h=0}^{\infty} \frac{h}{2^h})$ - $O(n)$ --- layout: false # Recap ## Priority queue ADT .small.center[ | Type | Push | Pop | Top | |-------------|-------------|-------------|-------------| | Sorted list | $O(n)$ | $O(1)$ | $O(1)$ | | BST | $O(\log n)$ | $O(\log n)$ | $O(\log n)$ | | Binary heap | $O(\log n)$ | $O(\log n)$ | $O(1)$ | ] ## Heapify - Heapify a vector of items - William's method * Insert one by one * $O(N \lg N)$ - Floyd's method * Create heap structure out of items * Percolate down from first internal node up to root * $O(N)$ ??? - William's approach: $\sum\_{h=0}^{\lfloor \log n \rfloor} 2^h O(h)$ - Floyd's approach: $\sum\_{h=0}^{\lfloor \log n \rfloor} \frac{n}{2^h} O(h)$ --- layout: true # Standard C++ containers --- The C++ Standard Library defines the implementation of a priority queue ADT. ``` std::priority_queue ``` ![:newline 1] Like `std::stack` and `std::queue`, only an *adaptor container* - Distinct combination of a sequence container and a set of *heap* methods - Container - By default `std::vector` - But can be any sequence container that can be randomly accessed (e.g., array, deque, string) - Set of *heap* methods - Defined by `#include <algorithm>` - `std::push_heap()`, `std::pop_heap()`, `std::make_heap()` --- ## Demo .footnotesize[ ```C template<typename T> void PrintQueue(T& q) { while (!q.empty()) { std::cout << q.top() << ", "; q.pop(); } std::cout << std::endl; } int main() { // (default) max priority queue std::priority_queue<int> q_max; // min priority queue std::priority_queue<int, std::deque<int>, std::greater<int>> q_min; for (auto n : {51, 43, 93, 18, 42, 99, 54, 2, 74}) { q_max.push(n); q_min.push(n); } // Pop and print values PrintQueue(q_max); PrintQueue(q_min); ... } ```  ] -- .lcol25[ ### Execution ] .rcol75.footnotesize[ ```terminal 99, 93, 74, 54, 51, 43, 42, 18, 2, 2, 18, 42, 43, 51, 54, 74, 93, 99, ``` ] ??? - Next slide is behind the scene so point out the different operations here --- ## Behind the scene - Using sequence container and heap methods .footnotesize[ ```C template<typename T> void PrintHeap(const std::vector<T> &v) { for (auto i : v) std::cout << i << ", "; std::cout << std::endl; } int main() { std::vector<int> v { 3, 1, 4, 1, 5, 9 }; std::make_heap(v.begin(), v.end()); // Heapify array PrintHeap(v); v.push_back(12); // Push() std::push_heap(v.begin(), v.end()); // Heapify PrintHeap(v); std::pop_heap(v.begin(), v.end()); // Pop() v.pop_back(); // Remove back PrintHeap(v); ... } ```  ] .lcol25[ ### Execution ] .rcol75.footnotesize[ ```terminal 9, 5, 4, 1, 1, 3, 12, 5, 9, 1, 1, 3, 4, 9, 5, 4, 1, 1, 3, ``` ]