class: center, middle name: title # CS 10C - Graphs ![:newline] .Huge[*Prof. Ty Feng*] ![:newline] .Large[UC Riverside - WQ 2026] ![:newline 6]  .footnote[Copyright © 2026 Joël Porquet-Lupine and Ty Feng - [CC BY-NC-SA 4.0 International License](https://creativecommons.org/licenses/by-nc-sa/4.0/)] ??? - We will start this topic by talking a little bit about the problem that started the graph theory, which I thought was quite interesting --- layout: true # The Seven Bridges of Königsberg --- ## Context - Paper published by Leonhard Euler in 1736 - Regarded as the first in history of graph theory ![:newline 1] ## Problem .lcol[ - City of Königsberg in old Prussia - Split in four pieces: 2 mainland portions and 2 islands - Interconnected by 7 bridges ![:newline 1] - Question: is it possible to walk through the city, crossing each bridge once and only once? ] .rcol[ 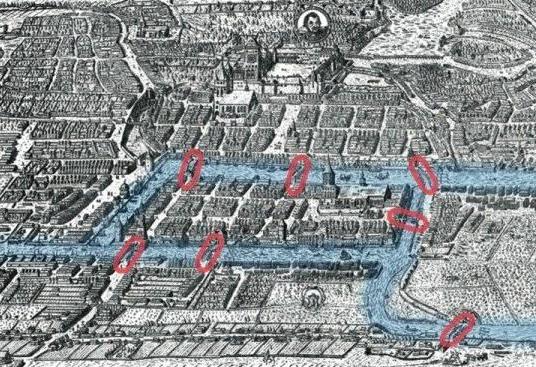 ] ??? - Königsberg, Prussia (former german empire, even the capital city for a while) - Now Kaliningrad, Russia -- ![:flush 1] ### Solution - Euler proved that the problem had no solution - Developed new technique of analysis to support his proof --- ## Representation - Reformulate the problem in abstract terms - Land mass: *vertex* (or node) - Bridge: *edge* - Resulting representation is a *graph* ![:newline 1] .lcol[ 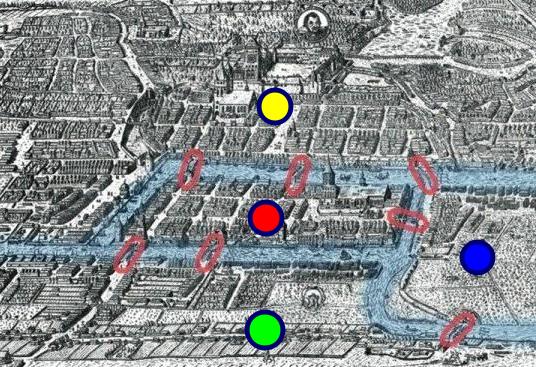 ] .rcol[  ] ![:flush 0] ## Analysis - Need graph to be *connected* - Possibility of a walk depends on the degrees of the nodes --- ## Euler's proposals ### Eulerian path .lcol66[ - Aka Euler walk - Path traversing all edges exactly once - Only possible if graph has exactly zero or two nodes of odd degree - If two nodes of odd degree: start path at one and end at the other ] .rcol33[  ] ??? - Not possible for the bridge problem because all four nodes are of odd degree -- ![:flush 1] ### Eulerian circuit .lcol66[ - Aka Euler tour - Path traversing all edges with *same* starting and ending point - Only possible if all nodes are of even degree ] .rcol33[  ] ??? - Every time you "enter" a node via an edge, you need to "leave" the node by another edge - Need a symmetry, provided by even number of edges --- layout: true # Introduction --- ## Graphs - Set of **vertices** connected pairwise by **edges** - Extremely versatile, apply to thousands of practical applications - Many known algorithms to manipulate graphs ## Examples -- ### Subway map  .center.footnotesize[London tube map] --- ### Protein-protein interactions  .center.footnotesize[*C. elegans* protein interaction network] --- ### Facebook world friendship 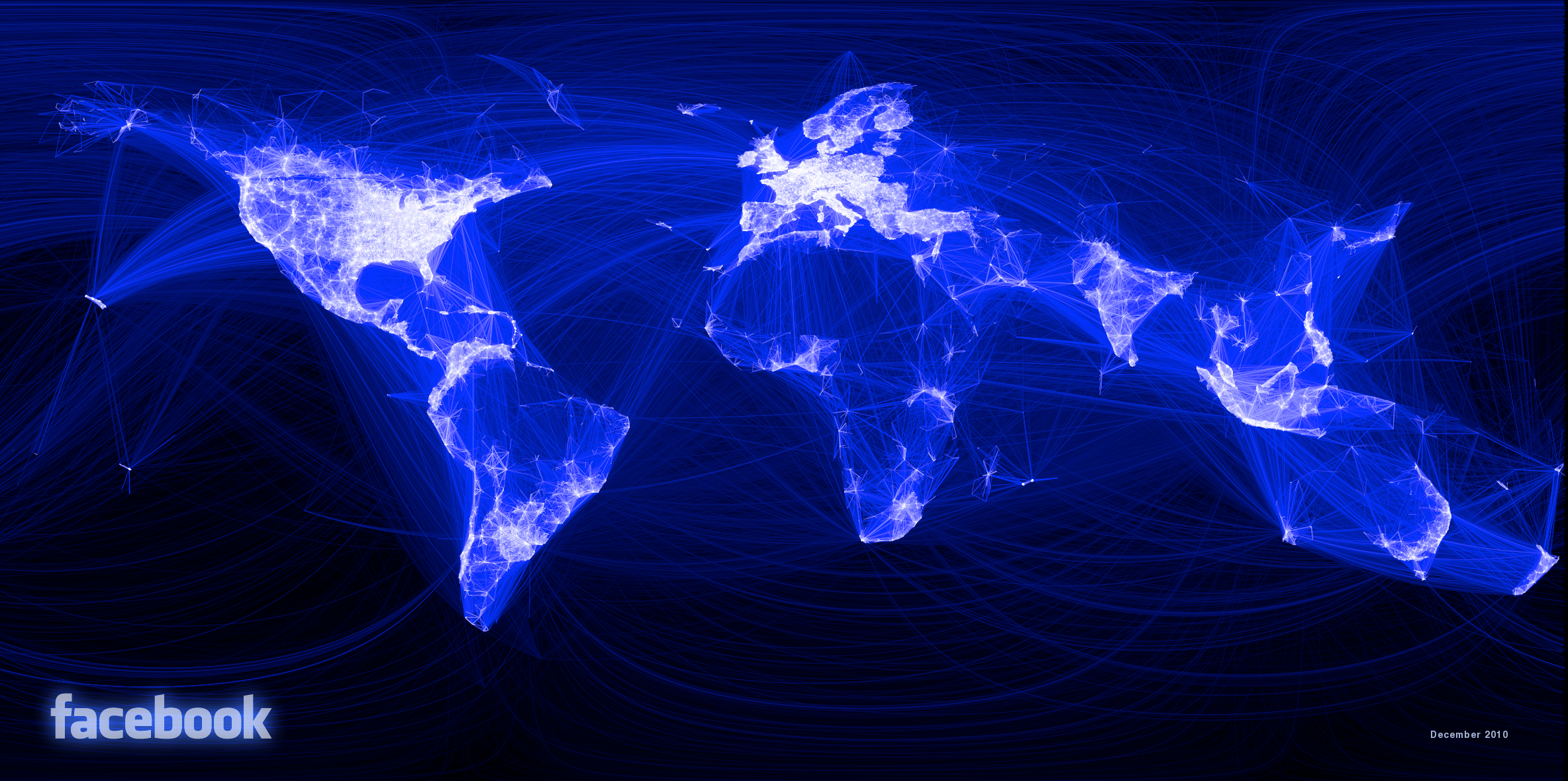 .center.footnotesize[Social graph of 500 million people] --- ## Other application examples | Graph | Vertex | Edge | |----------------|------------------------------|----------------------| | LAN | Computer | Fiber optic cable | | Circuit | Gate, register, processor | Wire | | Finance | Stock, currency | Transactions | | Transportation | Street intersection, airport | Roads, airway routes | | Neural network | Neuron | Synapse | | Molecule | Atom | Bond | .footnote[\* From Sedgewick and Wayne, Princeton] .comment[ --- template: title ] --- layout: true # Graphs --- ## Definition - $G = (V, E)$ - $V$: set of *vertices* (or nodes) - $E$: set of *edges* (or links, arcs) --pair of two vertices -- ![:newline 1] .lcol75[ ## Undirected graph - Edges are all bi-directional ![:newline 1] - $ V = \\{A, B, C\\} $ - $ E = \\{\\{A, B\\}, \\{A, C\\}\\} $ ] .rcol25[  ] -- ![:flush 1] .lcol75[ ## Directed graph - Edges are uni-directional - Aka *digraphs* ![:newline 1] - $ V = \\{A, B, C\\} $ - $ E = \\{(A, B), (B, A), (C, A)\\} $ ] .rcol25[  ] ??? - Default is usually considered undirected --- .lcol75[ ## Degree of a vertex - Number of edges incident on vertex Only relevant for digraphs: - *In-degree:* number of edges incident to vertex - *Out-degree:* number of edges incident from vertex ] .rcol25[  ] -- ![:flush 1] ### 0-degree vertices  - Note that all of these graphs are valid! --- ## Main types of graph .lcol75[ ### Multigraph - A multigraph is a graph (directed or not) in which *multiple edges* and *loops* are allowed ] .rcol25[ #### Loops  ] .rcol25[ #### Multiple edges  ] -- .lcol75[ ### Simple graph - A simple graph is an undirected graph which has neither multiple edges nor loops - *This is the default definition of a graph* ] -- ![:flush 1] .lcol66[ ### Weighted graph - In a weighted graph, each edge is associated with a weight - Weights usually represent costs, lengths, capacities, etc. - Depends on the problem at hand ] .rcol33[  ] --- ## Path .lcol66[ - Sequence of vertices connected by edges ![:newline 1] - *Length:* number of edges along the path - *Weight:* sum of all edge weights along the path ] .rcol33[  ] -- ![:flush 1] ## Cycle .lcol66[ - Path whose first and last vertices are the same - A graph containing no cycles is said to be *acyclic* ] .rcol33[  ] --- ## Classes of graph .lcol75[ ### Connected graph - Vertices are *connected* if there is a path between them - For directed graphs - *Strongly connected* if there is a directed path from every vertex to every other vertex - *Weakly connected* otherwise connected if we ignored edge directions ![:newline 1] - A connected graph is a graph in which every pair of vertices are connected - If every pair of vertices is joined by an edge, the graph is *complete* ] .rcol25[  ] -- ![:flush 1] .lcol75[ ### Disconnected graph - A disconnected graph is composed of two or more connected components ] .rcol25[  ] --- ### Dense graph .lcol66[ - A graph is dense if it contains a large number of edges - $E = \Theta(V^2)$ ] .rcol33[  ] ??? - Maximum number of edges in a graph? - In digraph, if V nodes, then V-1 edges per node - Total: V * V-1 - In undirected graph, same divided by 2 -- ![:flush 1] ### Sparse graph .lcol66[ - A graph is sparse if it contains much less than the maximum number of possible edges - $E = \Theta(V)$ ] .rcol33[  ] --- ## Trees - Trees are a specific kind of graph too!  ![:newline 2] - *Undirected*, *acyclic*, *connected*, *rooted* graph - A *forest* is a graph in which multiple connected components are trees ??? - Actually, a graph is a tree is when breaking one link, it becomes a forest --- template: title --- layout: false # Recap ## Graphs - Definition: $G = (V, E)$ * $V$: set of *vertices* (or nodes) * $E$: set of *edges* (or links, arcs) --pair of two vertices ### Terminology - Undirected vs directed graphs - Degree of a vertex * In-degree, out-degree - Multigraph * Allows multiple directed edges in the same direction between two nodes - Weighted graphs * Associate weight to each edge - Notion of path * Sequence of edges between two nodes - Connected vs disconnect graphs - Dense vs sparse graphs - Trees are a specific kind of (*rooted*) graphs ??? - Recap of vocab introduced last time - Today, focus on digital representation of graphs --- layout: true # Graph representation --- ## Example graph .lcol66[ ### Visual representation  ] ??? - Simple graph * Disconnected -- .rcol33[ ### Textual representation ```console $ cat tinyG.txt 13 0 5 4 3 0 1 9 12 6 4 5 4 0 2 11 12 9 10 0 6 7 8 9 11 5 3 ``` ] ![:flush 1] - Problem: how to represent this graph in code? ??? - Assume we define a file format to represent simple graphs * First line is number `N` of nodes in graph (nodes are numbered from 0 to N-1) * Followed by list of edges describing how these nodes are connected * Show quickly ![:newline 1] - First, before figuring out how to represent, what do we expect from a graph in the first place? - Let's look at the API --- ## Possible API .small[ ```C class Graph { // Generic Graph API public: // Create empty graph with V vertices Graph(int V); // Create graph from input stream Graph(std::ifstream &ifs); // Add an edge v-w void AddEdge(int v, int w); // Vertices adjacent to v std::vector<int> Adj(int v); // Number of vertices int V(); // Number of edges int E(); ... }; ```  ] ??? - Build a graph - Either from an empty graph - Or from file - Add edge between two vertices - For most if not all graph algorithms, get all the vertices adjacent to a vertex - Number of vertices total, and number of edges -- - Multiple implementation approaches - List of edges - Adjacency matrix - Adjacency lists ??? ![:newline 1] - Pronounce "Ad-jay-cency" - One of the most important operation is `Adj()` - GPS: when getting to an intersection, explore possibilities to make a choice --- ## List of edges ### Principle - Array or list of all $E$ edges, defined by two vertex numbers ![:newline 1] .lcol75[  ] .rcol25[  ] ??? - Pretty much, just reading the file and getting the data - Mention that we could add a third column for the weight for a weighted graph - Now, how to define that in code? --- ### Implementation .lcol.footnotesize[ ```C class Graph { ... private: // Edge list implementation std::vector<std::pair<int, int>> edges; int nv; }; ```  ![:newline 1] ```C int Graph::V() { return nv; } int Graph::E() { return edges.size(); } ```  ] -- .rcol.footnotesize[ ```C Graph::Graph(int V) : nv(V) {} Graph::Graph(std::ifstream &ifs) { // Get number of vertices ifs >> nv; // Go through all the edges and add them int v, w; while (ifs >> v >> w) AddEdge(v, w); } ```  ] -- .rcol.footnotesize[ ![:newline 1] ```C void Graph::AddEdge(int v, int w) { edges.emplace_back(v, w); } ```  ] ??? - use `emplace_back` to have the pair object be created by `emplace_back` directly - with `push/emplace_back(make_pair(v, w))`, might copy the object -- .lcol[ ![:newline 1] ] .lcol.footnotesize[ ```C std::vector<int> Graph::Adj(int v) { std::vector<int> v_edges; for (auto &e : edges) { if (e.first == v) v_edges.push_back(e.second); else if (e.second == v) v_edges.push_back(e.first); } return v_edges; } ```  ] ??? - Need to check all edges for `v` in first or second position - I could also have pushed the two variants of the edge in AddEdge() * `edges.emplace_back(v, w); edges.emplace_back(w, v);` - Would multiply by 2 the space occupation, but simplifies the code in Adj() since only need to check `e.first` in that case -- .rcol[ ![:newline 2] - Space occupation of $\Theta(E)$ - Search for adjacent edges in $O(E)$ - Access edge $v-w$ in $O(E)$ ] ??? ![:newline 1] - Can you think of a way to search edges in O(log E) - Store edges in a BST instead of a simple vector! - Now, how to get edge(v, w) in O(1)? - next slide --- ## Adjacency matrix ### Principle - Two-dimensional $V$x$V$ boolean array - For each edge $v-w$ in graph: `adj[v][w] = adj[w][v] = true` ![:newline 1] .lcol40[  ] .rcol60[ 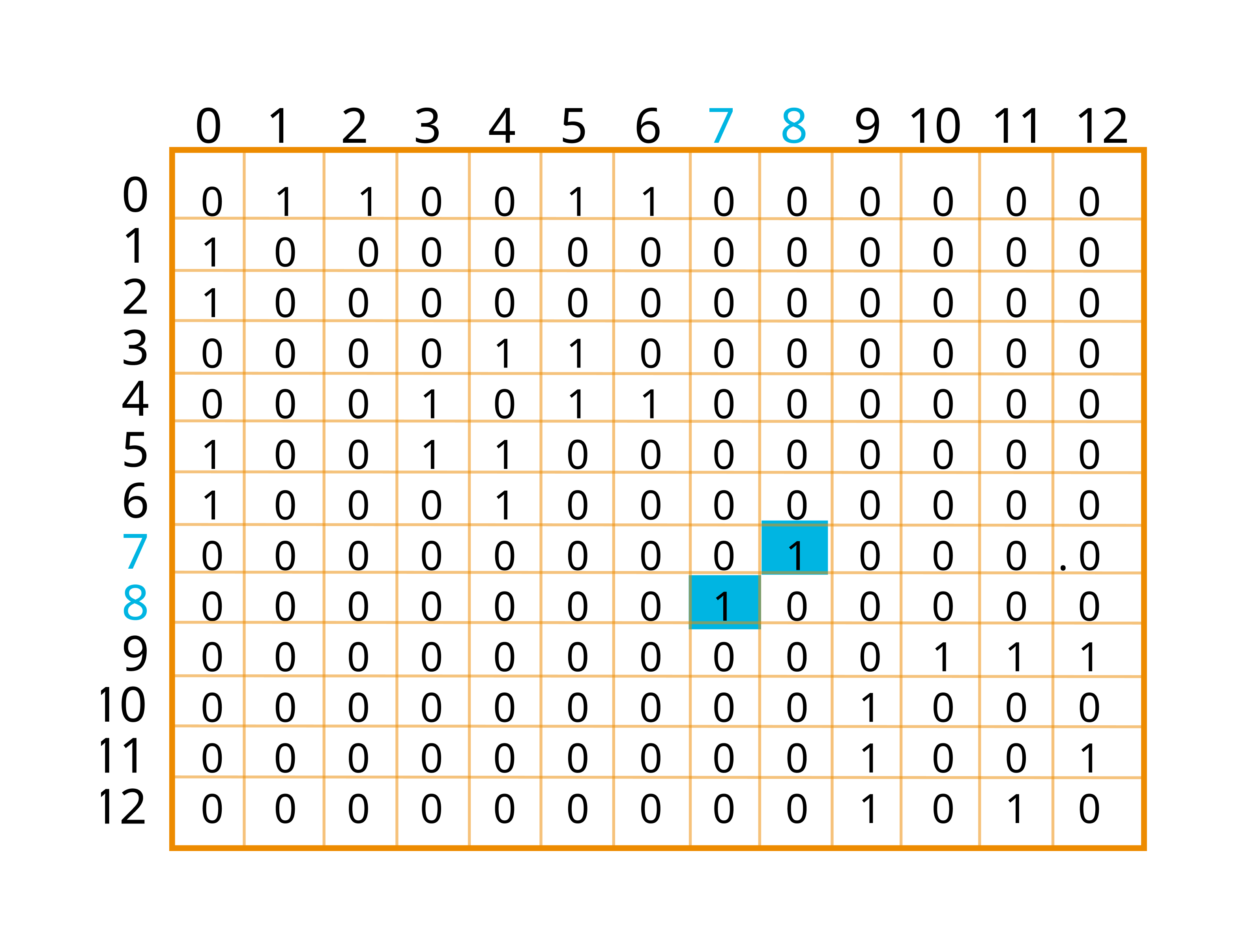 ] ??? - Notice the symmetry when representing undirected graph - Can you already detect some flaws of such representation - Bad for sparse graphs - Take space to represent nonexistent data, which is useless for data structures - Could contain directly the weight for each edge - Sentinel value for when edge does not exist - Eg, +infinity/-infinity depending on case --- ### Implementation .lcol.footnotesize[ ```C class Graph { ... private: // Adjacency matrix implementation std::vector<std::vector<bool>> adj_m; int nv; int ne = 0; }; ```  ```C int Graph::V() { return nv; } int Graph::E() { return ne; } ```  ] -- .rcol.footnotesize[ ```C Graph::Graph(int V) : adj_m(V, std::vector<bool>(V, false)), nv(V) {} ```  ] ??? - Allocation of both dimensions - Fill out 2-D matrix with 0s -- .rcol.footnotesize[ ```C Graph::Graph(std::ifstream &ifs) { // Get number of vertices ifs >> nv; // Allocate 2-D matrix adj_m.resize(nv, std::vector<bool>(nv, false)); // Go through all the edges and add them int v, w; while (ifs >> v >> w) AddEdge(v, w); } ```  ```C void Graph::AddEdge(int v, int w) { adj_m[v][w] = true; adj_m[w][v] = true; ++ne; } ```  ] ??? - Use resize() afterwards because can't allocate in the same way as other constructor * Need to read number of vertices from file first - Here, we do keep track of both directions for undirected edges! -- .lcol.footnotesize[ ```C std::vector<int> Graph::Adj(int v) { std::vector<int> v_edges; for (int w = 0; w < V(); w++) { if (adj_m[v][w]) v_edges.push_back(w); } return v_edges; } ```  ] -- .rcol[ - Access edge $v-w$ in $O(1)$ ] .lcol[ - Space occupation of $\Theta(V^2)$ ] .wide[ - Search for adjacent edges in $O(V)$ ] ??? ![:newline 1] - Summary - Space occupation bad (compared to ideal with edge list) - Edge access great, O(1) - Search edge comparable to edge list (here, good for dense graph; edge list good for sparse graphs) - best of both worlds - space occupation linear - fast edge search - fast edge access --- ## Adjacency lists ### Principle - Vertex-indexed array of lists - For each vertex, list of all adjacent vertices ![:newline 1] .lcol[  ] .rcol[  ] ??? - Here, we list only destination nodes * We could use pairs of destination-weight for weighted graphs --- ### Implementation .lcol.footnotesize[ ```C class Graph { ... private: // Adjacency lists implementation std::vector<std::vector<int>> adj_l; int nv; int ne = 0; }; ```  ```C int Graph::V() { return nv; } int Graph::E() { return ne; } ```  ] -- .rcol.footnotesize[ ```C Graph::Graph(int V) : adj_l(V), nv(V) {} Graph::Graph(std::ifstream &ifs) { // Get number of vertices ifs >> nv; // Allocate lists of vertices adj_l.resize(nv); // Go through all the edges int v, w; while (ifs >> v >> w) AddEdge(v, w); } ```  ```C void Graph::AddEdge(int v, int w) { adj_l[v].push_back(w); adj_l[w].push_back(v); ++ne; } ```  ] -- .lcol[ ![:newline 1] ] .lcol.footnotesize[ ```C std::vector<int> Graph::Adj(int v) { return adj_l[v]; } ```  ] -- ![:flush 0.5] - Space occupation of $\Theta(V + E)$ - Search for adjacent edges in $O(degree(v))$ - Because returning copy of vector - Access edge $v-w$ in $O(degree(v))$ ??? - Actually twice E when undirected graph since each edge is duplicated - search is still in $O(degree(v))$, because we're returning a copy of the vector --- ## Conclusion - In practice, use adjacency-lists representation most of the time - Most graph algorithms are based on iterating over vertices adjacent to $v$ - Most graphs tend to be sparse ![:newline 2] ### Complexity summary .footnotesize[ | Representation | Space | `AddEdge()` | Access $v-w$ edge | `Adj(v)` | |------------------|-------|-----------------|-------------------|-------------| | List of edges | $E$ | $1$ (amortized)| $E$ | $E$ | | Adjacency matrix | $V^2$ | $1$ | $1$ | $V$ | | Adjacency lists | $V+E$ | $1$ (amortized)| $degree(v)$ | $degree(v)$ | ] --- template: title --- layout: false # Recap .lcol[ ## Graph representation  ] .rcol[ ### Edge list  ] .lcol[ ### Adjacency matrix  ] .rcol[ ### Adjacency list  ] --- layout: true # Graph traversal --- ## What we know about ADT traversal so far .lcol40[ ### List-based ADTs - Start from first element - Move to next one - Repeat until end of sequence  ] -- .rcol60[ ### Tree-based ADTs - Start from root - Until reaching leaf nodes 1. Depth-first order - Explore vertically using a stack (or recursively) 1. Breadth-first order: - Explore horizontally using a queue  ] --- ## Graph traversal strategy .lcol[ - Pick a vertex in the graph 1. Depth-first traversal 1. Breadth-first traversal - Until no more vertices to visit ] .rcol[  ] --- ## Depth-first search principle .lcol[ - Systematically search through a graph - Mimic maze exploration - Common implementations - Recursive - Stack-based ] .rcol[  ] -- ![:flush 2] .small[ ```bash function DFS(Graph G, vertex v): Mark v as visited for all edges from v to w in G.Adj(v) do if vertex w is not marked as visited then Recursively call DFS(G, w) ``` ] --- ## Breadth-first search principle .lcol[ - Equal progression on all paths - Mimic water spreading out - Common implementation - Queue-based ] .rcol[  ] -- .wide.small[ ```bash function BFS(Graph G, vertex v): Mark v as visited Put v on FIFO queue Q while Q is not empty do Remove least recently added vertex w for all edges from w to x in G.Adj(w) do if vertex x is not marked as visited then Mark x as visited Add x to Q ``` ] --- ## Design pattern for graph processing Decouple graph *representation* from graph *processing* 1. Create graph-representation object 1. Pass graph to graph-processing object 1. Query graph-processing object for information ![:newline 3] -- .lcol[  .center.footnotesize[Graph representation] ] .rcol[  .center.footnotesize[Depth-first search on vertex 0] ] .rcol.small[ ![:newline 2] Queries: - Is vertex 0 connected to vertex 4? - Is vertex 0 connected to vertex 7? ] --- ### Example for Depth-first search .lcol[ #### Graph processing class .footnotesize[ ```C class DepthFirstPaths { public: // Find paths in @G from vertex @s DepthFirstPaths(Graph G, int s); // Return true if path from s to @v bool HasPathTo(int v); // Return path from s to @v, if any std::list<int> PathTo(int v); ... }; ```  ] ] -- .rcol[ #### Queries .footnotesize[ ```C Graph G(ifs); DepthFirstPaths dfp(G, s); for (int v = 0; v < G.V(); v++) { std::cout << v << ": "; if (dfp.HasPathTo(v)) for (auto &w : dfp.PathTo(v)) std::cout << w << ", "; else std::cout << "no path"; std::cout << std::endl; } ```  ] ] -- ![:flush 1] #### Execution .lcol.footnotesize[ ```terminal $ ./graph_dfs tinyG.txt 0 0: 0, 1: 0, 1, 2: 0, 2, 3: 0, 5, 4, 3, ... 7: no path ... ``` ] .rcol[  ] --- ## Depth-first search implementation .lcol.footnotesize[ ```C class DepthFirstPaths { ... private: std::vector<bool> marked; std::vector<int> prev; int s; // Recursive depth-first search void dfs(Graph G, int v); }; ```  ] ??? - `marked`: keep track of visited nodes - `prev`: keep memory of path (for each node, know the predecessor) -- .rcol.footnotesize[ ```C DepthFirstPaths::DepthFirstPaths(Graph G, int s) : marked(G.V(), false), prev(G.V(), -1), s(s) { dfs(G, s); } ```  ] -- .rcol.footnotesize[ ```C void DepthFirstPaths::dfs(Graph G, int v) { marked[v] = true; for (auto &w : G.Adj(v)) { if (!marked[w]) { dfs(G, w); prev[w] = v; } } } ```  ] -- .lcol.footnotesize[ ```C std::list<int> DepthFirstPaths::PathTo(int v) { std::list<int> path; if (HasPathTo(v)) { for (int w = v; w != s; w = prev[w]) path.push_front(w); path.push_front(s); } return path; } ```  ] .rcol.footnotesize[ ```C bool DepthFirstPaths::HasPathTo(int v) { return marked[v]; } ```  ] ??? ![:newline 1] - Run example showing prev[] and marked[] ``` 0 -> 1 | v 3 -> 4 -> 2 5 ``` --- ## Breadth-first search implementation .lcol.footnotesize[ ```C class BreadthFirstPaths { ... private: std::vector<bool> marked; std::vector<int> prev; int s; // Iterative breadth-first search void bfs(Graph G, int s); }; ```  ] -- .rcol.footnotesize[ ```C BreadthFirstPaths::BreadthFirstPaths(Graph G, int s) : marked(G.V(), false), prev(G.V(), -1), s(s) { bfs(G, s); } void BreadthFirstPaths::bfs(Graph G, int s) { std::queue<int> q; marked[s] = true; q.push(s); while (!q.empty()) { int v = q.front(); q.pop(); for (auto &w : G.Adj(v)) { if (!marked[w]) { marked[w] = true; q.push(w); prev[w] = v; } } } } ```  ] ??? - Implementation of the other functions is the same -- .lcol[ #### Demo  .scriptsize[ ```terminal $ ./graph_bfs tinyG.txt 0 0: 0, 1: 0, 1, 2: 0, 2, 3: 0, 5, 3, ... 7: no path ... ``` ] ] --- template: title --- layout: false # Recap ## Graph traversals .lcol[ ### Depth-first search (DFS) - Follow path as deep as possible before backtracking  .footnotesize[ ```C class DepthFirstPaths { ... private: std::vector<bool> marked; std::vector<int> prev; int s; // Recursive depth-first search void dfs(Graph G, int v); }; ```  ] ] .rcol[ ### Breadth-first search (BFS) - Traverse nodes layer by layer  .footnotesize[ ```C class BreadthFirstPaths { ... private: std::vector<bool> marked; std::vector<int> prev; int s; // Iterative breadth-first search void bfs(Graph G, int s); }; ```  ] ] ??? - Generic ways of traversing a graph - Now, let's look at more targeted algorithms --- layout: true # Shortest paths --- ## Principle - Find shortest paths from a source vertex $s$ to all the other vertices - One of the most important graph algorithms - Map routing (GPS) - Routing network messages (internet communication) - Solve Rubik's cube! (fastest path to solution) ??? - Solve Rubik's cube - Each vertex is a cube's combination - Each edge is a possible move - Minimum set of moves from current combination to perfect one -- ![:newline 1] .lcol[ ### Unweighted graphs  ] .rcol[ ### Weighted graphs  ] -- .lcol[ - Use standard breadth-first search! ] -- .rcol[ - Need specific algorithm, such as *Dijkstra's algorithm* ] --- ## Dijkstra's algorithm - Developed in 1956, published in 1959 - Edges are weighted and all weights are positive - Similar principle as BFS but follows shortest path ### Pseudo-code .footnotesize[ ```python Dijkstra(Graph, source): create vertex list Q for each vertex v in Graph: # Initialization dist[v] ← INFINITY # Unknown distance from source to v prev[v] ← UNDEFINED # Previous node in optimal path from source add v to Q # All nodes initially in Q (unvisited nodes) dist[source] ← 0 # Distance from source to source while Q is not empty: u ← vertex in Q with min dist[u] # Node with the least distance # will be selected first remove u from Q for each neighbor v of u: # where v is still in Q. alt ← dist[u] + length(u, v) if alt < dist[v]: # A shorter path to v has been found dist[v] ← alt prev[v] ← u return dist[], prev[] ``` ] ??? - Note that this pseudo differs slightly from the one given in homework (if djikstra given for P4) * This one is more high level, it doesn't optimize the queue + Search for min dist[u] in O(Q) + For homework, using an indexed min-priority queue * It adds all the vertices to the queue beforehand + For homework, only if a vertex is reachable, it is added to queue --- ### Dijkstra's algorithm: demo .lcol[  ] -- .rcol[  ] -- .lcol[  ] -- .rcol[  ] -- .lcol[  ] -- .rcol.small[ ![:newline 1] - All shortest paths from `A`: ``` A to B: A -> B (1) A to C: A -> B -> D -> C (4) A to D: A -> B -> D (2) ``` ] Another visualization can be found at [graph-viz.html](graph-viz.html). --- ## Dijkstra's algorithm limitation ### Critical assumption .alert[ **Dijkstra's algorithm requires all edge weights to be non-negative** ] - If graph contains negative edge weights, Dijkstra may produce **incorrect results** - The greedy approach assumes that once a vertex is processed, the shortest path to it has been found - Negative weights violate this assumption 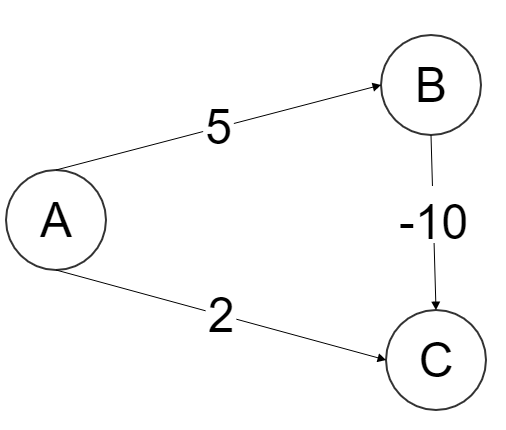 --- ## Other shortest path algorithms - Dijkstra's algorithm variants - Using different priority queue implementations (e.g., binary heap, Fibonacci heap) - Improves time complexity based on priority queue operations - Bellman-Ford algorithm - Edge weights can be negative - A\* search algorithm - Search best path between one source and one destination - Uses heuristics to speed up the search - Widely used for pathfinding in video games - Floyd-Warshall algorithm, and Johnson's algorithm - Both find shortest paths between *all* pairs of vertices - Different time complexities and use cases ??? - Such a common problem with graphs, that multiple algorithms exist - Each optimized for a specific aspect - A\* - Take into account current know distance (like Dijkstra) but also consider the estimated remaining distance to goal (the heuristics is how to perform the estimate) - In a 2D map, the heuristics can be the euclidian distance between current position and destination --- layout: true # Minimum spanning tree --- ## Definition .lcol66[ - A *spanning tree* is the tree of edges that connects all the vertices in a graph - Minimizing the number of edges ] .rcol33[  ] ??? - A graph may have multiple possible spanning trees - If graph is disconnected, forest of spanning trees -- ![:flush 0.5] .lcol66[ - In a weighted graph, a *minimum spanning tree* is a spanning tree with the lowest total weight - E.g., used in network design (communication, electrical, road, etc.) ] .rcol33[  ] ??? ![:newline 1] - Instead of D-E, could be A-D - example network design: - connect buildings on campus via fiber optic - find best edges for deploying cable -- ![:flush 2] ## Prim's algorithm 1. Initialize tree with a vertex, chosen arbitrarily in the graph 1. Pick the edge with lowest weight between tree and one of the vertices not in the tree yet 1. Repeat previous step until all vertices are in the tree --- ### Prim's algorithm: demo .lcol[  ] -- .rcol[  ] -- .lcol[  ] -- .rcol[  ] -- .lcol[  ] -- .rcol[  ] --- layout: false # Other graph algorithms .lcol66[ - Topological sorting - Linear ordering of vertices such that all edge directions are respected - E.g., prerequisite requirements for CS major curriculum ] .rcol33[  ] ??? - More than one Topological sort is possible -- ![:flush 0.5] .lcol66[ - Graph connectivity - Find strongly connected components - E.g., Facebook friend recommendations ] .rcol33[  ] ??? - node c and h should probably friends -- ![:flush 0.5] .lcol66[ - Max flow problem - Determine maximum flow between source and sink - E.g., find best network routing ] .rcol33[  ] ??? - Get max flow rate between two nodes * E.g., network traffic -- ![:flush 1] - And many more... --- layout: false count: false class: center, middle # Thank you for a great quarter!! ??? - Great crowd in here - You went through all of the assignments and examinations with success - Just the final left, but I'm sure you'll do great --- count: false # Ready for the next step! .lcol75[  ] .rcol25[ - Upper-div courses - Job/internship interviews ] ??? - Have a great break and see you around